This post is also available in:
![]()
![]()
Introducción: La Paradoja de la Era de los Datos
Su empresa está sentada sobre una mina de oro. Ahora mismo.
Sus sistemas CRM, su Google Analytics, sus redes sociales, sus hojas de cálculo… cada una de estas plataformas genera miles de puntos de datos cada día. Datos sobre sus clientes, sus operaciones, sus finanzas. Es una cantidad de información sin precedentes.
Entonces, ¿por qué tomar decisiones estratégicas sigue sintiéndose como navegar en la niebla?
Esta es la gran paradoja de la era digital: la mayoría de las empresas son «ricas en datos, pero pobres en información». Tienen los datos, sí, pero están dispersos, desordenados y desconectados. Es como tener todos los ingredientes para un banquete gourmet, pero tirados por el suelo de la cocina.
En esta guía definitiva, vamos a darle la receta y las herramientas para cocinar ese banquete. Le mostraremos cómo construir un Pipeline de Datos Inteligente, un sistema automatizado que no solo recolecta y almacena su información, sino que la limpia, la enriquece y la transforma en insights accionables que impulsan decisiones estratégicas y crecimiento rentable. Olvídese de los reportes que nadie lee; vamos a construir la máquina que le dirá exactamente qué hacer a continuación.
1. ¿Qué es un Pipeline de Datos? (Y qué lo hace «Inteligente»)
En su forma más simple, un pipeline de datos (o tubería de datos) es un sistema que mueve datos de un punto A a un punto B. Por ejemplo, de su base de datos de ventas a una herramienta de visualización. Un pipeline básico es como una tubería de agua: simplemente transporta el recurso.
Pero, ¿qué pasaría si esa tubería pudiera también purificar el agua, analizar su composición, enriquecerla con minerales y dirigirla automáticamente al lugar que más la necesita, todo en tiempo real?
Eso es un Pipeline Inteligente.
No se limita a mover datos; los transforma a lo largo del camino. Es un sistema orquestado que utiliza la automatización, la inteligencia artificial y el machine learning para convertir datos crudos y caóticos en un activo refinado y de alto valor.
La diferencia fundamental:
- Pipeline Básico: Responde a la pregunta «¿Qué pasó?». (Ej. «Vendimos 100 unidades el mes pasado»).
- Pipeline Inteligente: Responde a las preguntas «¿Por qué pasó?», «¿Qué pasará después?» y «¿Qué deberíamos hacer al respecto?». (Ej. «Vendimos 100 unidades porque nuestra campaña en LinkedIn tuvo un 30% más de engagement con los clientes del sector tecnológico. Nuestro modelo predice que si duplicamos la inversión en ese segmento el próximo mes, las ventas aumentarán un 15%. Deberíamos reasignar el presupuesto ahora.»)
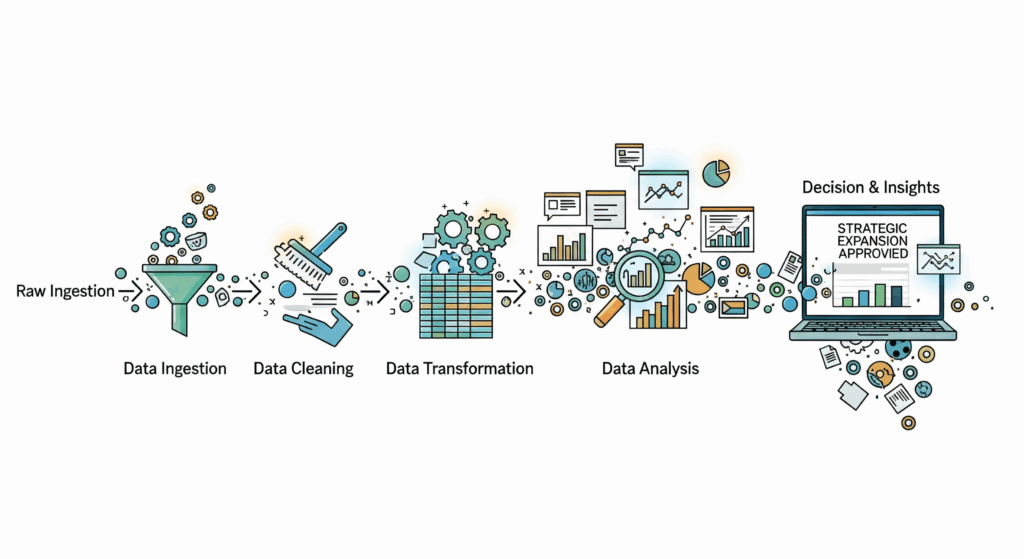
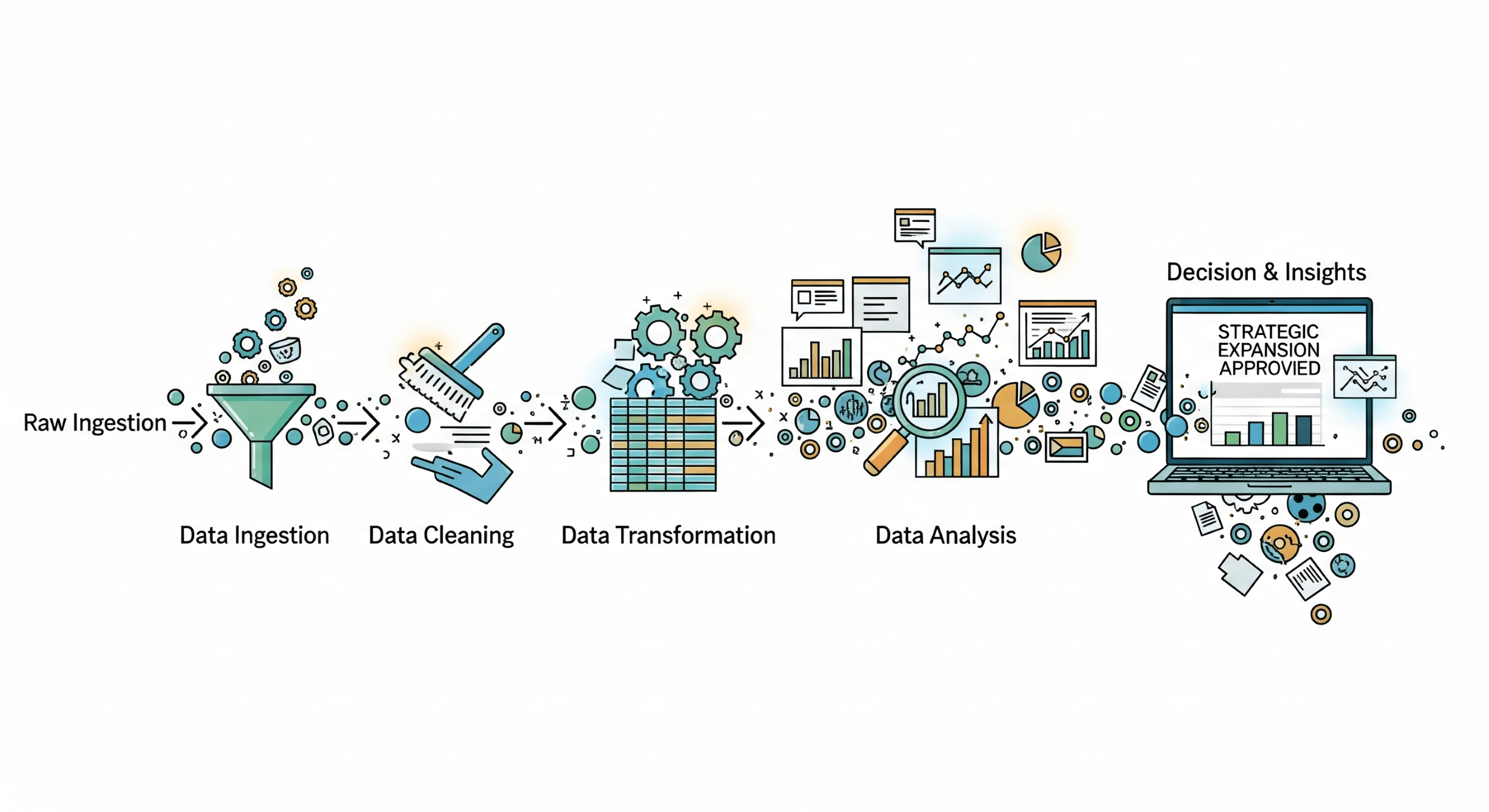
2. La Anatomía de un Pipeline Inteligente: Las 5 Etapas Cruciales
Construir un pipeline inteligente es un proceso metódico. Cada etapa se construye sobre la anterior, creando un sistema robusto y escalable. Vamos a desglosar cada una.
Etapa 1: Ingesta (La Recolección de Materia Prima)
Aquí es donde todo comienza. El objetivo es recolectar datos de todas sus fuentes dispares y centralizarlos.
Fuentes Comunes de Datos:
- Datos de Clientes: CRM (Salesforce, HubSpot), plataformas de email marketing (Mailchimp).
- Datos de Comportamiento Web/App: Google Analytics, Adobe Analytics, Mixpanel.
- Datos de Marketing: Plataformas de anuncios (Google Ads, Facebook Ads), redes sociales.
- Datos Transaccionales: Bases de datos de la empresa (MySQL, PostgreSQL), sistemas ERP.
- Datos de Terceros: APIs públicas, bases de datos demográficas, datos de mercado.
Métodos de Ingesta:
- Ingesta por Lotes (Batch): Los datos se recolectan y se mueven en bloques a intervalos programados (ej. cada 24 horas). Es ideal para análisis históricos y reportes que no requieren inmediatez.
- Ingesta en Tiempo Real (Streaming): Los datos se capturan y procesan en el momento en que se generan. Es crucial para aplicaciones como la detección de fraudes o la personalización web en tiempo real.
Herramientas Populares:
- Plataformas de ELT/ETL: Fivetran, Stitch, Airbyte. Estas herramientas ofrecen «conectores» preconstruidos a cientos de fuentes de datos, automatizando gran parte del proceso.
- APIs Personalizadas: Para fuentes de datos únicas o internas, a menudo se construyen scripts personalizados (generalmente en Python).
Etapa 2: Almacenamiento (La Bodega y el Almacén)
Una vez recolectados, los datos necesitan un lugar donde vivir. Aquí es donde entran dos conceptos clave: el Data Lake y el Data Warehouse.
- Data Lake (Lago de Datos): Piense en esto como una gran bodega donde se almacena la materia prima en su estado crudo y sin procesar. Se guardan los datos tal como llegan, sin una estructura predefinida. Es barato, flexible y perfecto para que los científicos de datos exploren y encuentren patrones ocultos.
- Data Warehouse (Almacén de Datos): Este es el almacén organizado. Contiene datos que ya han sido limpiados, estructurados y optimizados para el análisis. La información está ordenada en tablas con esquemas definidos, lo que hace que las consultas para los reportes de negocio sean increíblemente rápidas.
La estrategia moderna no es elegir uno u otro, sino usar ambos. Los datos primero aterrizan en el Data Lake y luego se procesan y se mueven al Data Warehouse para el consumo de los analistas de negocio.
Herramientas Populares (Basadas en la Nube):
- Google BigQuery
- Amazon Redshift
- Snowflake
Etapa 3: Transformación y Enriquecimiento (El Proceso de Refinado)
Esta es la etapa donde ocurre la verdadera «inteligencia» y donde la mayoría de los proyectos de datos fracasan si no se hace bien. Transformar datos crudos en información confiable es un trabajo meticuloso.
Procesos Clave:
- Limpieza (Cleansing): Eliminar registros duplicados, corregir errores tipográficos (ej. «Mexico» vs. «México»), estandarizar formatos (ej. convertir todas las fechas a AAAA-MM-DD) y manejar valores nulos.
- Estructuración (Structuring): Convertir datos no estructurados, como el texto de un correo electrónico, en un formato estructurado con campos definidos (remitente, asunto, fecha, cuerpo).
- Enriquecimiento (Enrichment): Este es un multiplicador de valor. Consiste en combinar datos de diferentes fuentes para crear una visión más completa. Por ejemplo, tomar la dirección de correo de un cliente y enriquecer su perfil con datos demográficos de una API externa o con su historial de compras del sistema ERP.
- Agregación (Aggregation): Calcular métricas y KPIs. Por ejemplo, a partir de una tabla de ventas individuales, se calcula el «Total de Ventas por Región y por Mes».
Herramientas Populares:
- dbt (Data Build Tool): La herramienta de facto para la transformación de datos. Permite a los analistas escribir transformaciones en SQL de una manera versionable y comprobable, como si fuera software.
- Scripts Personalizados (Python/Spark): Para transformaciones muy complejas o que involucran machine learning.
Etapa 4: Análisis y Machine Learning (La Extracción de Oro)
Con datos limpios y enriquecidos en nuestro Data Warehouse, ahora podemos hacer las preguntas importantes.
Los Cuatro Niveles de Análisis:
- Análisis Descriptivo (¿Qué pasó?): La base de todo. Son los dashboards y reportes que muestran KPIs históricos. (Ej. «Nuestras ventas en el último trimestre fueron de $1.2M»).
- Análisis Diagnóstico (¿Por qué pasó?): Profundizar para entender las causas. (Ej. «Las ventas aumentaron porque la campaña ‘Verano2025’ tuvo una tasa de conversión un 25% más alta que el promedio»).
- Análisis Predictivo (¿Qué pasará?): Aquí entra el Machine Learning. Se construyen modelos que aprenden de los datos históricos para predecir resultados futuros. (Ej. «Nuestro modelo de propensión predice que los clientes que han comprado el Producto A y el Producto B tienen un 70% de probabilidad de comprar el Producto C en los próximos 30 días»).
- Análisis Prescriptivo (¿Qué deberíamos hacer?): El nivel más avanzado. Recomienda acciones específicas para optimizar un resultado. (Ej. «El sistema recomienda ofrecer un descuento del 10% en el Producto C a este segmento de clientes para maximizar la probabilidad de conversión»).
Etapa 5: Activación y Visualización (Poner los Insights a Trabajar)
Los insights más brillantes son inútiles si se quedan en una hoja de cálculo. La etapa final consiste en hacer que esos datos sean accesibles y accionables para toda la organización.
Visualización:
- Herramientas: Looker Studio (antes Google Data Studio), Tableau, Microsoft Power BI.
- Propósito: Crear dashboards interactivos y fáciles de entender que permitan a los equipos de negocio explorar los datos y responder a sus propias preguntas sin necesidad de un analista. Un buen dashboard no solo muestra números, cuenta una historia.
Activación (Cerrando el Círculo): Aquí es donde el pipeline inteligente se conecta de nuevo a las operaciones del negocio.
- Alertas Automatizadas: Si el inventario de un producto clave baja de un umbral, se envía una alerta automática al equipo de compras a través de Slack.
- Sincronización Inversa (Reverse ETL): Los insights generados en el Data Warehouse (como la puntuación de propensión de un cliente) se envían de vuelta a las herramientas operativas como el CRM (Salesforce) o la plataforma de marketing.
- Resultado: Ahora, un vendedor puede ver directamente en el perfil de un cliente en Salesforce: «Puntuación de Propensión: 92/100. Recomendar Producto C». La decisión está integrada en su flujo de trabajo diario.
Conclusión: Su Pipeline es su Ventaja Competitiva
Hemos desglosado el viaje completo: desde el caos de los datos crudos dispersos hasta la claridad de un insight accionable entregado a la persona correcta en el momento correcto.
Construir un Pipeline de Datos Inteligente no es un proyecto de TI de una sola vez; es la construcción de un sistema nervioso central para su empresa. Es un activo estratégico que le permite aprender más rápido, moverse más rápido y tomar decisiones más inteligentes que sus competidores.
Empiece pequeño, enfóquese en un problema de negocio claro y siga las cinco etapas. Al hacerlo, pasará de ser una empresa que simplemente tiene datos a ser una empresa que prospera gracias a ellos.
¿Listo para Construir su Propio Motor de Decisiones?
Deje de Adivinar, Empiece a Decidir
En una llamada estratégica, identificáremos el primer paso para convertir sus datos en un activo rentable.
Si siente que sus datos podrían estar trabajando más para usted, agende una llamada estratégica. Analizaremos su ecosistema de datos actual y le mostraremos el camino para convertirlo en su mayor activo.
Ahora es su turno: ¿Cuál es la pregunta de negocio más importante que le gustaría poder responder con sus datos, pero que actualmente no puede? Déjenos su respuesta en los comentarios.
This post is also available in:
![]()
![]()